Automatic Recognition of Personality Profiles Using EEG Functional Connectivity during Emotional Processing
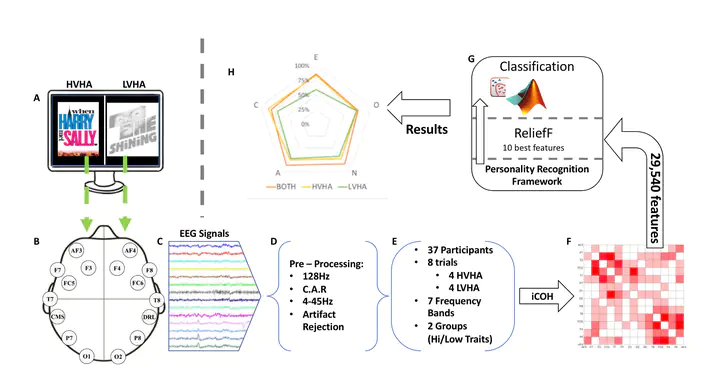 This figure describes the stages of our research methodology. In the beginning, high valence high arousal (HVHA) and low valence high arousal (LVHA) short videos were displayed to the participants of the AMIGOS experiment (A) and their affective responses were recorded using the EEG modality (B). Then, the EEG recordings (C) were pre-processed (D), while (E) shows the experimental details. The construction of brain networks using iCOH (F) followed next and the extraction of features based on the network’s weights as well as on graph theoretical properties was performed. ReliefF (G) concluded on the 10 best features per trait, and was used three times; the first time, for sorting the features extracted during HVHA block of clips; the second time, for sorting the features extracted during LVHA block of clips; and one more time, for sorting all the aforementioned features together (BOTH). Finally, the classification stage (H) yields the presented prediction accuracy for each one of the five dimensions of personality (neuroticism (N): 83.8%, extraversion (E): 83.8%, openness (O): 73%, agreeableness (A): 86.5%, and conscientiousness (C): 83.8%).
This figure describes the stages of our research methodology. In the beginning, high valence high arousal (HVHA) and low valence high arousal (LVHA) short videos were displayed to the participants of the AMIGOS experiment (A) and their affective responses were recorded using the EEG modality (B). Then, the EEG recordings (C) were pre-processed (D), while (E) shows the experimental details. The construction of brain networks using iCOH (F) followed next and the extraction of features based on the network’s weights as well as on graph theoretical properties was performed. ReliefF (G) concluded on the 10 best features per trait, and was used three times; the first time, for sorting the features extracted during HVHA block of clips; the second time, for sorting the features extracted during LVHA block of clips; and one more time, for sorting all the aforementioned features together (BOTH). Finally, the classification stage (H) yields the presented prediction accuracy for each one of the five dimensions of personality (neuroticism (N): 83.8%, extraversion (E): 83.8%, openness (O): 73%, agreeableness (A): 86.5%, and conscientiousness (C): 83.8%).
Abstract
Personality is the characteristic set of an individual’s behavioral and emotional patterns that evolve from biological and environmental factors. The recognition of personality profiles is crucial in making human–computer interaction (HCI) applications realistic, more focused, and user friendly. The ability to recognize personality using neuroscientific data underpins the neurobiological basis of personality. This paper aims to automatically recognize personality, combining scalp electroencephalogram (EEG) and machine learning techniques. As the resting state EEG has not so far been proven efficient for predicting personality, we used EEG recordings elicited during emotion processing. This study was based on data from the AMIGOS dataset reflecting the response of 37 healthy participants. Brain networks and graph theoretical parameters were extracted from cleaned EEG signals, while each trait score was dichotomized into low- and high-level using the k-means algorithm. A feature selection algorithm was used afterwards to reduce the feature-set size to the best 10 features to describe each trait separately. Support vector machines (SVM) were finally employed to classify each instance. Our method achieved a classification accuracy of 83.8% for extraversion, 86.5% for agreeableness, 83.8% for conscientiousness, 83.8% for neuroticism, and 73% for openness.
Manousos Klados
Associate Professor of Psychology
Manousos Klados is a mathematician, with a M.Sc. in Computational Neuroscience and a PhD in the borders of Affective, Cognitive and Computation Neurosciences. Currently he is an Assoc. Professor in Psychology at University of York Europe Campus - CITY College.